[点晴永久免费OA]苹果 iCloud 发布这么多年,如何实现存储数十亿个数据库还不卡顿的?
当前位置:点晴教程→点晴OA办公管理信息系统
→『 经验分享&问题答疑 』
作者 | Leonardo Creed 翻译 | 苏宓 出品 | CSDN(ID:CSDNnews) 在众多科技巨头中,相比 Google、微软、Meta 等公司,苹果无论是在 iOS 系统,还是很多新兴技术研发方面,都保持着一定的神秘感,鲜少有人知道苹果公司的基础设施是如何构建出来的? 近日,软件工程师 Leonardo Creed 在查阅了大量的论文以及整理了多个技术细节之后,向众人分享了苹果是如何构建在线同步存储服务和云端计算服务 iCloud 的,也揭晓了它如何实现存储数十亿个数据库的。通过本篇文章,也希望给相关的从业者带来更多的思考与帮助。 以下为译文:
永恒的现实世界课程 苹果在 iCloud 和 CloudKit(他们的云计算后端服务)中使用了 FoundationDB 和 Cassandra。是的,标题没有错: 苹果确实在其极端多租户架构中存储了数十亿个数据库。 在正式解析其架构之前,我想分享自己发现的一些亮点,本篇文章以及苹果公司的许多经验与我之前写过的“Meta 无服务器平台架构”的在某些技术点上有些相似(https://read.engineerscodex.com/p/meta-xfaas-serverless-functions-explained)。
Cassandra 数据库 Cassandra 是一种开源的 NoSQL 数据库管理系统。它最初由 Facebook 开发,用于支持 Facebook 收件箱搜索功能。有趣的是,在 2021 年,Meta 自己开始用 ZippyDB 取代了大部分 Cassandra 的使用。 iCloud 部分采用了 Cassandra。据一家位于加利福尼亚州圣克拉拉的实时人工智能数据公司 DataStax(旗下主要产品基于 Apache Cassandra)称,苹果运行着世界上最大的 Cassandra 部署之一。 在他们发布的报告中,透露了苹果在 Cassandra 方面有:
对此,此前也有不少苹果前员工透露,iCloud 服务中 Cassandra 所管理的数据量高达数亿字节。每台服务器有多个 Cassandra 节点,这确保了 iCloud 数据的可用性接近 100%。 至此,苹果公司内部团队仍在积极改进 Cassandra。上个月,苹果公司的 Cassandra 存储工程经理 Scott Andreas 在一次会议上就 Cassandra 的未来发表了演讲。在苹果公司的招聘页面上,他们也在招聘分布式系统工程师时通常会提到 Cassandra。 然而,CloudKit + Cassandra 的解决方案在实际应用中遇到了两个可扩展性限制,因此苹果工程团队后来引入并采用了 FoundationDB:
FoundationDB 和记录层解决了这两个问题。
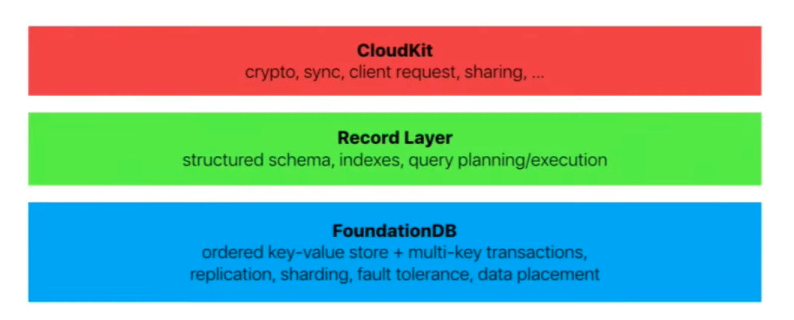
FoundationDB 数据库 苹果公司对 FoundationDB 的态度更为公开。他们在 2015 年收购了数据库公司 FoundationDB,并在此后发表了多篇论文,详细介绍了他们对 FoundationDB 的使用。 FoundationDB 是一种开源、分布式、事务性键值存储。它专为处理大量数据而设计,并且非常适合读/写工作负载和写入密集型工作负载。它还符合 ACID 标准。 Apple 在 CloudKit(Apple 的云计算后端服务)中广泛使用 FoundationDB 记录层。
在 FoundationDB 记录层的 GitHub 页面上,该团队详细介绍道: 记录层(Record Layer)是一个 Java API,它在 FoundationDB 的基础上提供了一个面向记录的存储,(非常)大致相当于一个简单的关系数据库,具有以下特点:
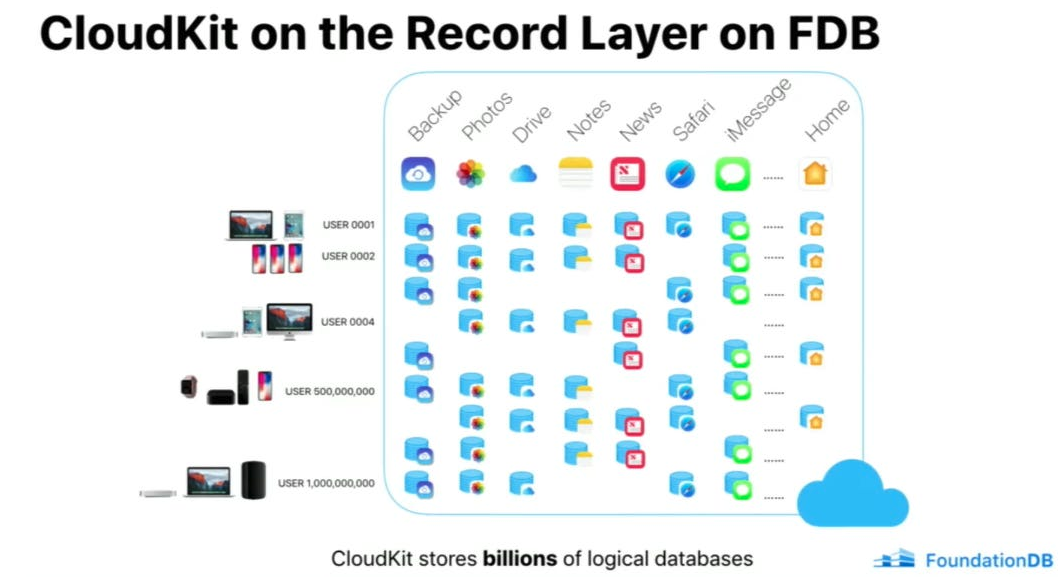
在 FoundationDB 记录层论文中,他们写道:“[FoundationDB 记录层用于]为服务于数亿用户的应用程序提供强大的抽象。CloudKit 使用记录层来托管数十亿个独立数据库,其中许多数据库具有共同的模式。”
为什么使用 FoundationDB 记录层? FoundationDB、Record Layer 和 CloudKit 的结构如下所示:
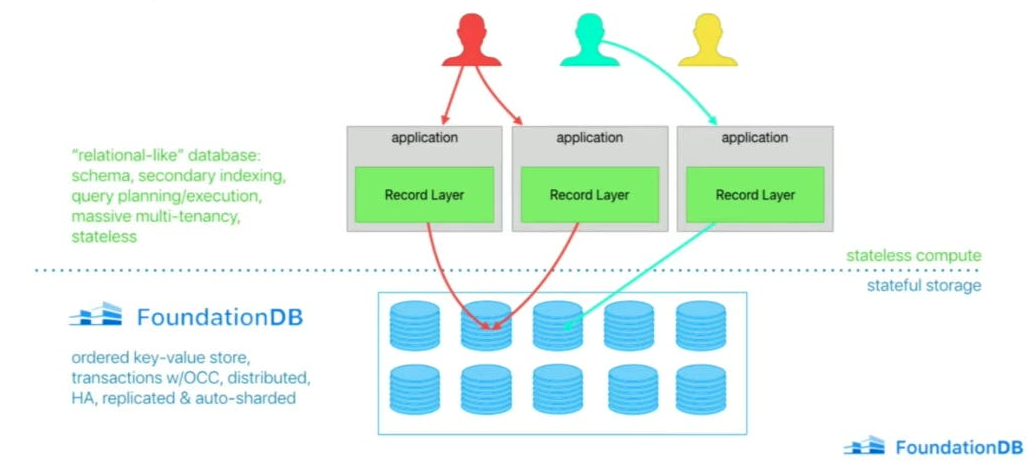
记录层允许苹果大规模支持多租户。 事实上,这样说有点言过其实。 记录层用于极端多租户,其中每个应用程序的每个用户都能获得独立的记录存储。这意味着记录层可托管数十亿个独立数据库,共享数千个模式。 这样更好!而且更令人印象深刻。
记录层之所以能够处理如此大规模的多租户问题,主要得益于两个基本的架构决策: 1. 该层以无状态方式运行,只需添加更多无状态实例,即可轻松扩展计算资源。
2. 该层使用记录存储抽象来有效管理资源分配和可扩展性。这种抽象代表了逻辑数据库的全部内容,包括序列化数据、索引和运行状态。
至此,我们可以粗略地了解一下苹果公司是如何构建 iCloud 的。
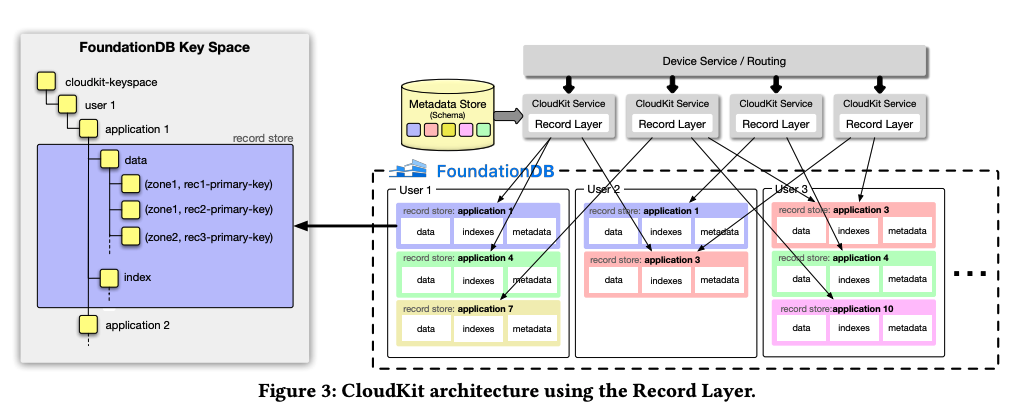
CloudKit 如何使用 FoundationDB 和记录层? 在 CloudKit 中,应用程序由“逻辑容器”(logical container)表示,该容器遵循定义的模式。该架构概述了实现高效数据检索和查询所需的记录类型、字段和索引。应用程序将其数据组织到 CloudKit 中的“区域”中,这样就可以对记录进行逻辑分组,以便有选择地与客户端设备同步。
对于每个用户,CloudKit 都会在 FoundationDB 中指定一个唯一的子空间。在这个子空间中,它会为用户与之交互的每个应用程序创建一个记录存储空间。从本质上讲,CloudKit 管理着大量逻辑数据库(用户数量乘以应用程序数量),每个数据库都包含自己的记录、索引和元数据集,总计数十亿个数据库。 当 CloudKit 收到来自客户端设备的请求时,它会通过负载均衡将该请求定向到可用的 CloudKit 服务进程。然后,该进程与特定的记录层记录存储进行交互,以满足请求。 CloudKit 会将已定义的应用程序模式转换为记录层中的元数据定义,并将其存储在单独的元数据存储区中。该元数据由 CloudKit 特定的系统字段进行扩充,这些字段用于跟踪记录的创建、修改时间和记录存储的区域。区域名称以主键为前缀,以便能够高效访问每个区域内的记录。除了用户定义的索引外,CloudKit 还管理用于内部目的的“系统索引”,例如通过保留按类型跟踪记录大小的索引来管理存储配额。 FoundationDB 和记录层共同为苹果公司解决了 4 个关键问题,这是单独使用 Cassandra 或单独使用 FoundationDB 都无法解决的。
问题一:个性化全文搜索 FoundationDB 帮助用户解决个性化全文搜索问题,以便快速访问数据。 苹果的系统利用 FoundationDB 的排序键顺序,可以快速搜索文本开头(前缀匹配),也可以进行更复杂的搜索(如查找相邻或按特定顺序排列的单词——近似搜索和短语搜索),而无需额外的开销。 在传统的搜索系统中,你通常需要在后台运行额外的进程来保持搜索索引的更新,但苹果的系统可以实时完成所有工作,这意味着一旦数据发生变化,搜索索引就会立即更新,无需额外的步骤。
问题二:高并发情况 有了 FoundationDB,CloudKit 可以流畅地处理同时发生的许多更新。 以前,在使用 Cassandra 时,CloudKit 需要依靠一个特殊的索引来跟踪每个区域的变化,从而实现跨设备的数据同步。当设备需要更新其数据时,它会检查该索引以查看新内容。但这种系统有一个缺点:当多个更新同时发生时,可能会造成冲突。 但在 FoundationDB 中,CloudKit 使用了一种特殊的索引,它能准确记录每次更改的顺序,而不会造成冲突。具体做法是为每次更改分配一个唯一的“版本”,当 CloudKit 需要同步时,它会查看这些版本,以确定设备错过了哪些更新。 然而,当 CloudKit 需要在不同的存储集群之间移动数据时(也许是为了更均匀地分配负载),事情就变得棘手了,因为每个集群都有自己的版本号,而这些版本号并不一致。 为了解决这个问题,CloudKit 为每个用户的数据提供了一个“移动计数”(称为 “化身”),每次将其数据传输到新的集群时,该计数都会增加。每次记录更新都包含用户当前的“化身”编号,确保即使在移动后,CloudKit 仍能通过查看化身编号和版本编号来确定正确的更新顺序。 在转到新系统时,CloudKit 面临着处理没有版本号的旧数据的挑战。苹果工程团队巧妙地克服了这一难题,他们通过使用一个特殊的功能,在新系统之前使用以前的系统对旧更新进行排序。这意味着无需对应用程序进行复杂的更改,也不会留下过时的代码。该函数考虑了版本、版本号和旧的更新计数器值,以保持记录的正确顺序。
问题三:高延迟查询 FoundationDB 是为高并发而不是低延迟而设计的。这意味着它可以同时处理大量任务,而不是专注于单个任务的速度。
为了充分利用这种设计,记录层的许多工作都是“异步”进行的——它将将来要完成的任务排队,允许同时完成其他工作。这种方法有助于掩盖这些任务中可能出现的任何延迟。 不过,FoundationDB 用来与其数据库通信的工具,是设计为使用单线程联网,一次只做一件事。在早期版本中,这种设置造成了系统中的交通堵塞,因为所有的事情都在等待轮到这个网络线程。记录层一直使用这种单线程方法,这导致了瓶颈。 为了改善这一问题,苹果减少了网络线程的工作量。现在,复杂的任务看起来速度更快了,因为系统同时在几个方面与数据库合作,而不是形成一个队列。这样,延迟或表面上的缓慢就被掩盖了,因为系统不会等一个任务完成后再开始另一个任务。
问题四:事务冲突 在 FoundationDB 中,如果一个事务正在读取某些键,而另一个事务同时修改了这些键,就会导致“事务冲突”。FoundationDB 通过提供对控制读取或写入时可能导致冲突的键集,来精确管理这些冲突。 一种避免不必要冲突的常用方法是,在键的范围内执行一种不会导致冲突的特殊读取,称为“快照”读取。如果这种读取发现了重要的键,事务将只标记那些可能发生冲突的特定键,而不是整个范围。这样可以确保事务只受对其结果有实际影响的变化的影响。 记录层使用这种策略来有效管理被称之为跳过列表的数据结构,这是其排序索引系统的一部分。不过,手动设置这些冲突范围可能比较麻烦,而且可能导致难以识别的错误,尤其是当它们与应用程序的主要逻辑混合在一起时。 因此,建议在 FoundationDB 基础上构建的系统创建更高级别的工具(如自定义索引)来处理这些模式。这种方法有助于避免将放宽冲突规则的责任留给每个客户端应用程序,从而导致错误和不一致。
对于 Leonardo Creed 的分享,不少开发者对此也有了更深度的思考: 亚马逊就是这么做 Aurora 的。将所有状态转移到对象存储层,而对象存储层也是处理过程的末端(经过 lb、前端、后端、数据库,最后到磁盘)。无状态基本上就是把所有东西都移到后端。 我敢肯定,Google 也在做同样的事情/已经开始做了。同时,这也使其“易于”横向扩展:只要你能在对象层面上进行抽象,你就可以扩展你的底层基础架构,以便只处理“对象”。 也有一位苹果前员工评论道: 遗憾的是,我在苹果公司工作时从未参与过这方面的工作(不过我参加过这方面的面试!),但几年前听到的这件事让我意识到了一些本该显而易见的事情:数据库和文件系统之间其实并没有什么区别。 从根本上说,它们做的是同一件事,只是针对特定问题集进行了优化。数据库适用于有适当索引的数据,而文件系统则适用于更为随意的数据。 如果你是一个足够聪明的工程师,你可以用数据库来定义文件系统,iCloud 就是一个很好的例子。就我个人而言,我利用这些知识使用 Cassandra 为 HLS 流存储视频数据块。这让我获得了很多 Cassandra 的分布式优势,但代价是不得不重新发明一些文件系统的东西。 参考链接: https://read.engineerscodex.com/p/how-apple-built-icloud-to-store-billions https://news.ycombinator.com/item?id=39028672 ———————————————— 版权声明:本文为CSDN博主「CSDN资讯」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/csdnnews/article/details/135687614 该文章在 2024/1/23 17:03:26 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886